8. Virtual Machine Reference¶
8.2. Startup options¶
The following command-line options are recognised by the Virtual Machine:
| Argument | Description |
|---|---|
-f filename |
Reads filename (which should contain Self source) immediately after startup (after reading the snapshot) and evaluates the contents. Useful for setting options, installing personal shortcuts, etc. |
-h |
Prints a message describing the options. |
-p |
Suppresses execution of the expression snapshotAction postRead after reading a snapshot. Useful if something in the startup sequence causes the system to break. |
-s snapshot |
Reads initial world from snapshot. A snapshot begins with the line exec Self -s $0 $@ which causes the Virtual Machine to begin execution with the snapshot. |
-w |
Don’t print warnings about object code. |
These options are provided for use by Self VM implementors:
| Argument | Description |
|---|---|
-F |
Discards any machine code saved in the snapshot. If the code in a snapshot is for some reason corrupted, but the objects are not, this option can be used to recover the snapshot. |
-l logfile |
Writes a log of events generated by the spy to logfile. |
-r |
Disables real timer interrupts. |
-t |
Disables all timers. |
Other command-line options are ignored by the Virtual Machine but are available at Self level via
the primitive _CommandLine.
The standard set of Self objects (built by the worldBuilder.self script) also defines -b (where the objects director is) and -o (for specifying build options)
8.3. System-triggered messages¶
Certain events cause the system to automatically send a message to the lobby. After reading a snapshot
the expression snapshotAction postRead is evaluated. This allows the Self world to
reinitialize itself — for example, to reopen windows.
There are other situations in which the system sends messages; see Run-time message lookup errors.
8.4. Run-time message lookup errors¶
If an error occurs during a message send, the system sends a message to the receiver of the message.
Any object can handle these errors by defining (or inheriting) a slot with the corresponding
selector. All messages sent by the system in response to a message lookup error have the same arguments.
The first argument is the offending message’s selector; the additional arguments specify
the message send type (one of ’normal’, ’implicitSelf’, ’undirectedResend’, ’directedResend’,
or ’delegated’), the directed resend parent name or the delegatee (0 if not
applicable), the sending method holder, and a vector containing the arguments to the message, if
any.
undefinedSelector:Type:Delegatee:MethodHolder:Arguments- The receiver does not understand the
message:no slot matching the selector can be found in the receiver or its ancestors. ambiguousSelector:Type:Delegatee:MethodHolder:Arguments- There is more than one slot matching the selector.
missingParentSelector:Type:Delegatee:MethodHolder:Arguments- The parent slot through which the resend should have been directed was not found in the sending method holder.
mismatchedArgumentCountSelector:Type:Delegatee:MethodHolder:Arguments- The number of arguments supplied to the
_Performprimitive does not match the number of arguments required by the selector. performTypeErrorSelector:Type:Delegatee:MethodHolder:Arguments- The first argument to the
_Performprimitive (the selector) wasn’t a canonical string.
These error messages are just like any other message. Therefore, it is possible that the object P
causing the error (which is being sent the appropriate error message) does not understand the error
message M either. If this happens, the system sends the first message (undefinedSelector:) to
the current process, with the error message M as argument. If this is not understood, then the system
suspends the process. If the scheduler is running, it is notified of the failure.
The system will also suspend a process if it runs out of stack space (too much recursion) or if a block is evaluated whose lexically-enclosing scope has already returned. Since these errors are nonrecoverable they cannot be caught by the same Self process; the scheduler, if running, is notified.
8.5. Low-level error messages¶
Five kinds of errors can occur during the execution of a Self program: lookup errors, primitive errors, programmer defined errors, non-recoverable errors, and fatal VM errors. All but the last of these are usually caught and handled by mechanisms in the programming environment, resulting in a debugger being presented to the user. However, if programs are run without the programming environment, or the error-handling mechanisms themselves are broken, low-level error facilities are used.
This section describes the various error messages presented by the low-level facilities. For each category or error, the general layout of error messages in that category will be explained along with the format of the stack trace. Then a “rogue’s gallery” of the errors in that category will be shown.
By default, errors are handled by a set of methods defined in module errorHandling. For all errors
except nonrecoverable and fatal VM errors, an object can handle errors in its own way by defining
its own error handling methods. If the object in which an error occurs neither inherits nor
defines error handling behavior, the VM prints out a low-level error message and a stack trace. The
system will also resort to this low-level message and trace if an error is encountered while trying
to handle an error.
8.6. An example¶
Here is an expression that produces an error in the current system:
“Self 7” 100000 factorial
The stack has grown too big.
(Self limits stack sizes, and cannot resume processes with stack overflows.)
To debug type “attach” or to show stack type “zombies first printError”.
The error arose because the recursive method factorial exceeded the size allocated for the process stack which resulted in a stack overflow.
The virtual machine currently allocates a fixed-size stack to each process and does not extend the stack on demand.
8.7. Lookup errors¶
Lookup errors occur when an object does not understand a message that is sent to it. How the actual message lookup is done is described in the Language Reference chapter.
- No ’foo’ slot found in shell <0>.
- The lookup found no slot matching the selector
foo. - No ’fish’ delegatee slot was found in <a child of lobby> <12>.
- The lookup found no parent slot
fish, which was explicitly specified as the delegatee of the message.
The lookup found two matchingsystemslots which means the message is ambiguous. The error message also says where the matching slots were found.
8.8. Programmer defined errors¶
These are explicitly raised in the Self program to report errors, e.g. sending the message first
to an empty list will cause such an error.
Error: first is absent.
Receiver is: list <7>.
Use the selectors error: and error:Arguments: to raise a programmer defined error.
8.9. Primitive errors¶
Primitive failures occur when a primitive cannot perform the requested operation, for example, because of a missing or invalid argument.
badTypeError: the ’_IntAdd:’ primitive failed.
Its receiver was shell <6>.
The primitive failed withbadTypeErrorbecause the shell in not an integer.
The selector 12 could not be sent to shell because it is not a string.
The primitive_Performexpects a string as its first argument.
The selector ’add:’ could not be sent to shell <0> because it does not take 2 arguments.
The primitive_Performreceived the wrong number of arguments.
There are many other kinds of possible primitive errors.
8.10. Nonrecoverable process errors¶
Errors that stop a process from continuing execution are referred to as nonrecoverable errors.
The stack has grown too big.
(Self 4.0 limits stack sizes, and cannot resume processes with stack
overflows.)
A stack overflow error occurs because the current version of Self allocates a fixed size stack for each process, and the stack cannot be expanded.
Self 4.0 cannot run a block after its enclosing method has returned.
(Self cannot resume this process, either.)
This error occurs if a block is executed after its lexically enclosing method has returned. This is called a “non-LIFO” block. Non-LIFO blocks are not supported by the current version of Self.
8.11. Fatal errors¶
In rare cases, the virtual machine may encounter a fatal error (e.g., a resource limit is exceeded or an internal error is discovered). When this happens, a short menu is displayed:
VM Version: 4.0.5, Tue 27 Jun 95 13:35:49 Solaris 2.x (svr4)
Internal error: signal 11 code 3 addr 4 pc 0x1ac768.
Do you want to:
1) Quit Self (optionally attempting to write a snapshot)
2) Try to print the Self stack
3) Try to return to the Self prompt
4) Force a core dump
Your choice:
The first two lines help the Self implementors locate the problem. Printing the Self stack may
provide more information about the problem but does not always work. Returning to the Self
prompt may be successful, but the system integrity may have been compromised as a result of the
error. The safest course is to attempt to write a snapshot (if there are unsaved changes), and then
check the integrity of the snapshot by executing the primitive _Verify after starting it. If there are
any error messages from the primitive, do not attempt to continue using the snapshot.
Since fatal errors usually arise from a bug in the virtual machine, please send the Self group a bug report, and include a copy of the error message if possible. If the error is reproducible please describe how to reproduce it (including a snapshot or source files may be helpful).
8.12. The initial Self world¶
The diagram on the following pages shows all objects in the “bare” Self world. In addition, literals like integers, floats, and strings are conceptually part of the initial Self world; block and object literals are created by the programmer as needed. All the objects in the system are created by adding slots to these objects or by cloning them. Table 8.1 lists all the initial objects and provides a short description for each. Reading in the world rearranges the structure of the “bare” Self world (see The Self World).
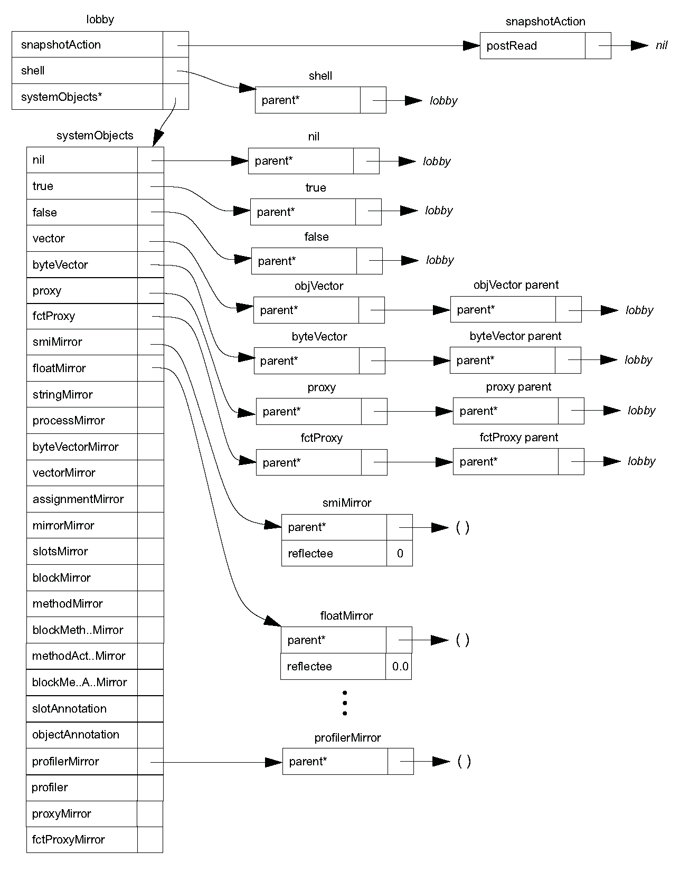
Fig. 8.1 The initial Self world (part 1)
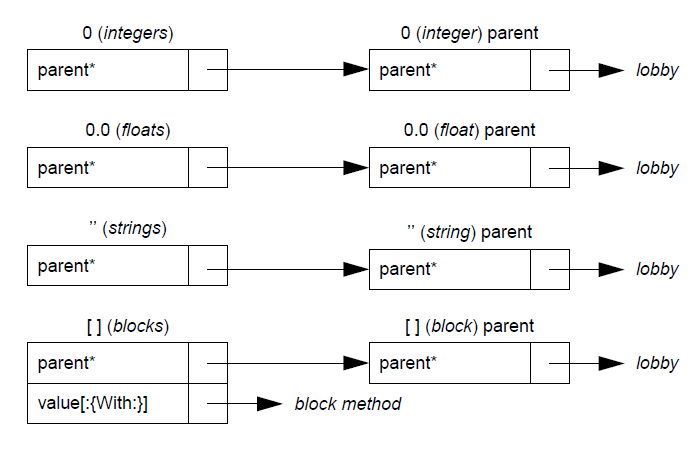
Fig. 8.2 The initial Self world (part 2)
| Object | Description |
|---|---|
lobby |
The center of the Self object hierarchy, and the context in which expressions typed in at the VM prompt, read in via _RunScript, or used as the initializers of slots, are evaluated. |
| Object | Description |
|---|---|
shell |
After reading in the world, shell is the context in which expressions typed in at the prompt are evaluated. |
snapshotAction |
An object with slot for the startup action (see System-triggered messages), postRead. This slot initially contains nil. |
systemObjects |
This object contains slots containing the general system objects, including nil, true, false, and the prototypical vectors and mirrors. |
| Object | Description |
|---|---|
nil |
The initializer for slots that are not explicitly initialized. Indicates “not a useful object.” |
true |
Boolean true. Argument to and returned by some primitives. |
false |
Boolean false. Argument to and returned by some primitives. |
vector |
The prototype for (normal) vectors. |
byteVector |
The prototype for byte vectors. |
proxy |
The prototype for proxy objects. |
fctProxy |
The prototype for fctProxy objects. |
vector parent |
The object that vector inherits from. Since all object vectors will inherit from this object (because they are cloned from vector), this object will be the repository for shared behavior (a traits object) for vectors. |
byteVector parent |
Similar to vector parent: the byteVector traits object. |
slotAnnotation |
The default slot annotation object. |
objectAnnotation |
The default object annotation object |
profiler |
The prototype for profilers. |
mirrors |
See below. |
| Literal | Description |
|---|---|
integers |
Integers have one slot, a parent slot called parent. All integers have the same parent: see 0 parent, below. |
0 parent |
All integers share this parent, the integer traits object. |
floats |
Floats have one slot, a parent slot called parent. All floats have the same parent: see 0.0 parent, below. |
0.0 parent |
All floats share this parent, the float traits object. |
canonical strings |
In addition to a byte vector part, a canonical string has one slot, parent, a parent slot containing the same object for all canonical strings (see ’’ parent below). |
'' parent |
All canonical strings share this parent, the string traits object. |
blocks |
Blocks have two slots: parent, a parent slot containing the same object for all blocks (see [ ] parent, below), and value (or value:, or value:With:, etc., depending on the number of arguments the block takes) which contains the block’s deferred method. |
[ ] parent |
All blocks share this parent, the block traits object. |
| Mirror | Description |
|---|---|
smiMirror |
Prototypical mirror on a small integer; the reflectee is 0. |
floatMirror |
Prototypical mirror on a float; the reflectee is 0.0. |
stringMirror |
Prototypical mirror on a canonical string; the reflectee is the empty canonical string (’’). |
processMirror |
Prototypical mirror on a process; the reflectee is the initial process. |
byteVectorMirror |
Prototypical mirror on a byte vector; the reflectee is the prototypical byte vector. |
objVectorMirror |
Prototypical mirror on object vectors; the reflectee is the prototypical object vector. |
assignmentMirror |
Mirror on the assignment primitive; the actual reflectee is an empty object. |
mirrorMirror |
Prototypical mirror on a mirror; the reflectee is slotsMirror. |
slotsMirror |
Prototypical mirror on a plain object without code; the reflectee is an empty object. |
blockMirror |
Prototypical mirror on a block. |
methodMirror |
Prototypical mirror on a normal method. |
blockMethodMirror |
Prototypical mirror on a block method. |
methodActivationMirror |
Prototypical mirror on a method activation. |
blockMethodActivationMirror |
Prototypical mirror on a block activation. |
proxyMirror |
Prototypical mirror on a proxy. |
fctProxyMirror |
Prototypical mirror on a fctProxy. |
profilerMirror |
Prototypical mirror on a profiler. |
All of the prototypical mirrors consist of one slot, a parent slot named parent. Each of
these parent slots points to an empty object (denoted in Fig. 8.1 by “( )”).
8.13. Option Primitives¶
This section has not been updated to include all options present in Self 4.0.
Option primitives control various aspects of the Self system and its inner workings. Many of
them are used to debug or instrument the Self system and are probably of little interest to users.
The options most useful for users are listed in Table 8.6; other option primitives can be found in Appendix
10.8 Primitives, and a list of all option primitives and their current settings can be printed with the
primitive _PrintOptionPrimitives.
| Name | Description |
|---|---|
_PrintPeriod[:] |
Print a period when reading a script file with _RunScript. Default: false. |
_PrintScriptName[:] |
Print the file name when reading a script file. Default: false. |
_Spy[:] |
Start the system monitor (see Appendix 10.7 for details). Default: false. |
_StackPrintLimit[:] |
Controls the number of stack frames printed by _PrintProcessStack. Default: 20. |
_DirPath[:] |
The default directory path for script files. |
Each option primitive controls a variable within the virtual machine containing a boolean, integer, or string (in fact, the option primitives can be thought of as “primitive variables”). Invoking the version of the primitive that doesn’t take an argument 1 returns the current setting; invoking it with an argument sets the variable to the new value and returns the old value.
Try running the system monitor with _Spy: true. The system monitor will continuously display
various information about the system’s activities and your memory usage.
8.14. Interfacing with other languages¶
This chapter describes how to access objects and call routines that are written in other languages than Self. We will refer to such entities as foreign objects and foreign routines. A typical use would be to make a function found in a C library accessible in Self. Three steps are necessary to accomplish this:
- Write and compile a piece of “glue” code that specifies argument and result types for the foreign routine and how to convert between these types and Self objects.
- Link the resulting object code to the Self virtual machine.
- Create a function proxy object (actually a
foreignFctobject) that represents the routine in the Self world.
Each of these steps is described in detail in the following sections.
8.14.1. proxy and fctProxy objects¶
A foreign object is represented by a proxy object in the Self world. A proxy object is an object
that encapsulates a pointer to the foreign object it represents. In addition to the pointer to the foreign
object, the proxy object contains a type seal. A type seal is an immutable value that is assigned
to the proxy object, when it is created. The type seal is intended to capture type information about
the pointer encapsulated in the proxy. For example, proxies representing window objects should
have a different type seal than proxies representing event objects. By checking the type seal against
an expected value whenever a proxy is “opened”, many type errors can be caught. The last property
of proxy objects is that they can be dead or live. If an attempt is made to use the pointer in a dead
proxy object, an error results (deadProxyError). Proxy objects may be explicitly killed, by
sending the primitive message _Kill to them. Furthermore, they are automatically killed after
reading in a snapshot. This way problems with dangling references to foreign objects that were not
included in the snapshot are avoided.
fctProxy objects are similar to proxy objects: they have a type seal and are either live or dead.
However, they represent a foreign routine, rather than a foreign object. A foreign routine can be invoked
by sending the primitive messages _Call, _Call:{With:},
_CallAndConvert{With:And:} to the fctProxy representing it. Note that fctProxy objects
are low-level. Most, if not all, uses of foreign routines should use the interface provided by foreignFct
objects.
Proxies (and fctProxies) can be freely cloned. However a cloned proxy will be dead. A dead proxy is revived when it is used by a foreign function to, e.g., return a pointer. The return value of the foreign function together with a type seal is stored into the dead proxy, which is then revived and returned as the result of the foreign routine call. The motivation for this somewhat complicated approach is that there will be several different kinds of proxies in a typical Self system. Different kinds of proxies may have different slots added, so rather than having the foreign routine figure out which kind of proxy to clone for the result, the Self code calling the foreign routine must construct and pass down an “empty” (dead) proxy to hold the result. This proxy is called a result proxy and it is the last argument supplied to the foreign function.
8.14.2. Glue code¶
Glue code is responsible for the transition from Self to foreign routines. It forms wrappers around
foreign routines. There is one wrapper per foreign routine. A wrapper takes a number of arguments
of type oop, and returns an oop (oop is the C++ type for “reference to Self object”). When a
wrapper is executed, it performs the following steps:
- Check that the arguments supplied have the correct types.
- Convert the arguments from Self representation to the representation that the foreign routine needs.
- Invoke the foreign routine on the converted arguments.
- Convert the return value of the foreign routine to a Self object and return this as the Self level result.
To make it easier to write glue code, a special purpose language has been designed for this. The result is that glue for a foreign routine will often consist of only a single line. The glue language is implemented as a set of C++ preprocessor macros. Therefore, glue code is just a (rather peculiar) kind of C++. Glue code can be in a file of its own, or – if it is glue for calling C++ routines – it can be in the same file as the foreign routines, and compiled with them.
To make the definition of the glue language available, the file containing glue code must contain:
# include "_glueDefs.c.incl"
The file “_glueDefs.c.incl” includes a bunch of C++ header files that contain all the definitions
necessary for the glue. Of the included files, “glueDefs.h” is probably the most interesting in this
context. It defines the glue language and also contains some comments explaining it.
Since different foreign languages have different type systems and calling conventions the glue language is actually not a single language, but one for each supported foreign language. Presently C and C++ are supported. See sections C glue and C++ glue for details.
8.14.3. Compiling and linking glue code¶
Since glue code is a special form of C++ code, a C++ compiler is needed to translate it. The way this is done may depend on the computer system and the available C++ compiler. The following description applies to Sun SPARCstations using the GNU g++ compiler.
A specific example of how to compile glue code can be found in the directory containing the toself
demo (see A complete application using foreign functions for further details). The makefile in that directory describes how to
translate a .c file containing glue into something that can be invoked from Self. This is a two
stage process: first the .c file is compiled into a .o file which is then linked (perhaps with other
.o files and libraries that the glue code depends on) into a .so file (a so-called dynamic library).
While the compilation is straightforward, several issues concerning the linking must be explained.
- Linking
- Before a foreign routine can be called it must be linked to the Self virtual machine. The linking can be done either statically, i.e. before Self is started, or dynamically, i.e. while Self is running. The Self system employs both dynamic and static linking, but users should only use dynamic linking, as static linking requires more understanding of the structure of the Virtual Machine. The choice between dynamic and static linking involves a trade-off between safety and flexibility as outlined in the following.
- Dynamic linking
- Dynamic linking has the advantage that it is done on demand, so only foreign routines that are actually
used in a particular session will be loaded and take up space. Debugging foreign routines is
also easier, especially if the dynamic linker supports unlinking. The main disadvantages with dynamic
linking is that more things can go wrong at run time. For example, if an object file containing
a foreign routine can not be found, a run time error occurs. The Sun OS dynamic linker,
ld.so, only handles dynamic libraries which explains why the second stage of glue translation is necessary. - Static linking
- Static linking, the alternative that was not chosen for Self, has the advantage that it needs to be done only once. The statically linked-in files will then be available for ever after. The main disadvantages are that the linked-in files will always take up space whether used or not in a given Self session, that the VM must be completely relinked every time new code is added, and that debugging is harder because there is no way to unlink code with bugs in. For these reasons the following examples all use dynamic linking.
8.14.4. A simple glue example: calling a C function¶
Suppose we have a C function that encrypts text strings in some fancy way. It takes two arguments,
a string to encrypt and a key, and returns a string which is the result of the encryption. To use this
function from Self, we write a line of C glue. Here is the entire file, “encrypt.c”, containing both
the encryption function and the glue:
/* Make glue available by including it. */
# include "incls/_glueDefs.c.incl"
/* Naive encryption function. */
char *encrypt(char *str, int key) {
static char res[1000];
int i;
for (i = 0; str[i]; ++i)
res[i] = str[i] + key;
res[i] = ’\0’;
return res;
}
/* Make glue expand to full functions, not just prototypes. */
# define WHAT_GLUE FUNCTIONS
C_func_2(string,, encrypt, encrypt_glue,, string,, int,)
# undef WHAT_GLUE
A few words of explanation: the last three lines of this file contain the glue code. First defining
WHAT_GLUE to be FUNCTIONS, makes the following line expand into a full wrapper function (defining
WHAT_GLUE to be PROTOTYPES instead, will cause the C_func_2 line to produce a function
prototype only). The line containing the macro C_func_2 is the actual wrapper for encrypt.
The “2” designates that encrypt takes 2 arguments. The meaning of the arguments, from left to
right are:
string,: specifies that encrypt returns a string argument.encrypt: name of function we are constructing wrapper for.encrypt_glue: name that we want the wrapper function to have.- An empty argument signifying that encrypt is not to be passed a failure handle (explained later).
string,: specifies that the first argument to encrypt is a string.int,: specifies that the second argument to encrypt is an int.
Having written this file, we now prepare a makefile to compile and link it. To do this, we can extend
the makefile in objects/glue/{sun4,svr4} (depending on OS in use) and then run make.
This results in the shared library file encrypt.so. Finally, to try it out, we can type these commands
(at the Self prompt or in the UI):
> _AddSlotsIfAbsent: ( | encrypt | )
lobby
> encrypt: ( foreignFct copyName: ’encrypt_glue’ Path: ’encrypt.so’ )
lobby
> encrypt
<C++ function(encrypt_glue)>
> encrypt value: ’Hello Self’ With: 3
’Khoor#Vhoi’
> encrypt value: ’Khoor#Vhoi’ With: -3
’Hello Self’
Comparing the signature for the function encrypt with the arguments to the C_func_2 macro it
is clear that there is a straightforward mapping between the two. One day we hope to find the time
to write a Self program that can parse a C or C++ header file and generate glue code corresponding
to the definitions in it. In the meantime, glue code must be handwritten.
8.14.5. C glue¶
C glue supports accessing C functions and data from Self. There are three main parts of C glue:
- Calling functions.
- Reading/assigning global variables.
- Reading/assigning a component in a struct that is represented by a proxy object in Self.
In addition, C++ glue for creating objects can be used to create C structs (see section C++ glue). The following sections describe each of these parts of C glue.
8.14.6. Calling C functions¶
The macro C_func_N where N is 0, 1, 2, ... is used to “glue in” a C function. The number N denotes
the number of arguments that should be given at the Self level, when calling the function. This
number may be different from the number of arguments that the C function takes since, e.g., some
argument conversions (see below) produce two C arguments from one Self object. Here is the
general syntax for C_func_N:
C_func_N(res_cnv,res_aux, fexp, gfname, fail_opt, c0,a0, ... cN,aN)
Compare this with the glue that was used in the encrypt example in section A simple glue example: calling a C function:
C_func_2(string,, encrypt, encrypt_glue,, string,, int,)
The meaning of each argument to C_func_N is as follows:
res_cnv,res_aux: these two arguments form a “conversion pair” that specifies how the result that the function returns is converted to a Self object. In theencryptexample, where the function returns a null terminated string,res_cnvhas the valuestring, andres_auxis empty. Table 8.7 lists all the possible values for theres_cnv,res_aux pair.fexpis a C expression which evaluates to the function that is being glued in. In the simplest case, such as in theencryptexample, the expression is the name of a function, but in general it may be any C expression, involving function pointers etc., which in a global context evaluates to a function.gfname: the name of the function which theC_func_Nmacro expands into. In theencryptexample, the convention of appending_glueto the C function’s name was used. When accessing a glued-in function from Self, the value ofgfnameis the name that must be used.fail_opt: there are two possible values for this argument. It can be empty (as in the example) or it can befail. In the latter case, the C function being called is passed an additional argument that will be the last argument and have type“void *”. Using this argument, the C function may abort its execution and raise an exception. The result is that the “IfFail block” in Self will be invoked.ci,ai: each of these pairs describes how to convert a Self level argument to one or more C level arguments. For example, in the glue forencrypt,c0,``a0`` specifies that the first argument toencryptis a string. Likewisec1,``a1`` specifies that the second argument is an integer. Note that in both these cases, the a-part of the conversion is empty. Table 8.7 lists all the possible values for theci,``ai`` pair.
Handling failures. Here is a slight modification of the encryption example to illustrate how the C function can raise an exception that causes the “IfFail block” to be invoked at the Self level:
/* Make glue available by including it. */
# include "incls/_glueDefs.c.incl"
/* Naive encryption function. */
char *encrypt(char *str, int key, void *FH) {
static char res[1000];
int i;
if (key == 0) {
failure(FH, "key == 0 is identity map");
return NULL;
}
for (i = 0; str[i]; i++)
res[i] = str[i] + key;
res[i] = ’\0’;
return res;
}
/* Make glue expand to full functions, not just prototypes. */
# define WHAT_GLUE FUNCTIONS
C_func_2(string,, encrypt, encrypt_glue, fail, string,, int,)
# undef WHAT_GLUE
Observe that the fail_opt argument now has the value fail and that the encrypt function
raises an exception, using failure, if the key is 0. There are two ways to raise exceptions:
extern "C" void failure(void *FH, char *msg);
extern "C" void unix_failure(void *FH, int err = -1);
In both cases, the FH argument is the “failure handle” that was passed by the C_func_N macro.
The second argument to failure is a string. It will be passed to the “IfFail block” in Self.
unix_failure takes an optional integer as its second argument. If this integer has the value -1,
or is missing, the value of errno is used instead. The integer is interpreted as a UNIX error number,
from which a corresponding string is constructed. The string is then, as for failure, passed
to the “IfFail block” at the call site in Self.
Warning
After calling failure or unix_failure a normal return must be done. The value returned (in the example NULL) is ignored.
8.14.7. Reading and assigning global variables¶
Reading the value of a global variable is done using the C_get_var macro. Assigning a value to
a global variable is done using C_set_var. Both macros expand into a C++ function that converts
between Self and C representation, and reads or assigns the variable. Here is the general syntax:
C_get_var(cnvt_res,aux_res, expr, gfname)
C_set_var(var, expr_c0,expr_a0, gfname)
A concrete example is reading the value of the variable errno, which can be done using:
C_get_var(int,, errno, get_errno_glue)
The meaning of the each argument is:
cnvt_res,``aux_res``: how to convert the value of the global variable that is being read to a Self object. In theerrnoexample,cnvt_resisintandaux_resis empty, since the type oferrnoisint. Thecnvt_res,``aux_res`` can be any one of the result conversions found in Table 8.7.expris the variable whose value is being read. In theerrnoexample, it is simplyerrno, but in general, it may actually be any expression that is valid in a global context, even an expression involving function calls.gfname: the name of the C++ function thatC_get_varorC_set_varexpands into.varis the name of a global variable that a value is assigned to. In general,var, may be any expression that in a global context evaluates to an l-value.expr_c0,``expr_a0``: when assigning to a variable, the value it is assigned is obtained by converting a Self object to a C value. Theexpr_c0,``expr_a0`` pair, which can be any one of the argument conversions listed in Table 8.7, specifies how to do this conversion.
8.14.8. Reading and assigning struct components¶
Reading the value of a struct component or assigning a value to it is similar to doing the same operations
on a global variable. The difference is that the struct must somehow be specified. This is
taken care of by the macros C_get_comp and C_set_comp. The general syntax is:
C_get_comp(cnvt_res,aux_res, cnvt_strc,aux_strc, comp, gfname)
C_set_comp(cnvt_strc,aux_strc, comp, expr_c0,expr_a0, gfname)
Here is an example, assigning to the sin_port field of a struct sockaddr_in (this struct is defined
in /usr/include/netinet/in.h):
struct sockaddr_in {
short sin_family;
u_short sin_port;
struct in_addr sin_addr;
char sin_zero[8];
};
The struct is represented by a proxy object:
char *socks = "type seal for sockaddr_in proxies";
C_set_comp(proxy,(sockaddr_in *,socks), .sin_port, short,,set_sin_port_glue)
The sockaddr_in example defines a function, set_sin_port_glue, which can be called from
Self. The function takes two arguments, the first being a proxy representing a sockaddr_in
struct, the second being a short integer. After converting types, set_sin_port_glue performs
the assignment:
(*first_converted_arg).sin_port = second_converted_arg.
In general the meaning of the C_get_comp and C_set_comp arguments is:
cnvt_res,aux_res: how to convert the value of the component that is being read to a Self object. Any of the result conversions found in Table 8.7 may be applied.cnvt_strc,aux_strc: the conversion that is applied to produce a struct upon which the operation is performed. In thesin_portexample, this conversion is a proxy conversion, implying that in Self, the struct whosesin_portcomponent is assigned is represented by a proxy object. In general, any of the argument conversions from Table 8.7 that results in a pointer, may be used.compis the name of the component to be read or assigned. In the sin_port example, this name is“.sin_port”. Note that it includes a “.”. This, e.g., allows handling pointers to int’s by pretending that it is a pointer to a struct and operating on a component with an empty name.gfname: the name of the C++ function thatC_get_comporC_set_compexpands into.expr_co,expr_a0: when assigning to a component, the value it is assigned is obtained by converting a Self object to a C value. Theexpr_co,expr_a0pair, which can be any one of the argument conversions listed in Table 8.7, specifies how to do this conversion.
8.14.9. C++ glue¶
Since C++ is a superset of C, all of C glue can be used with C++. In addition, C++ glue provides support for:
- Constructing objects using the new operator.
- Deleting objects using the delete operator.
- Calling member functions on objects.
Each of these parts will be explained in the following sections.
8.14.10. Constructing objects¶
In C++, objects are constructed using the new operator. Constructors may take arguments. The
macros CC_new_N where N is a small integer, support calling constructors with or without arguments.
Calling a constructor is similar to calling a function, so for additional explanation, please
refer to section Calling C functions. Here is the general syntax for constructing objects using C++ glue:
CC_new_N(cnvt_res,aux_res, class, gfname, c0,a0, c1,a1, ... cN,aN)
For example, to construct a sockaddr_in object, the following glue statement could be used:
CC_new_0(proxy,(sockaddr_in *,socks), sockaddr_in, new_sockaddr_in)
The meanings of the CC_new_N arguments are as follows:
cnvt_res,aux_res:the result of calling the constructor is an object pointer. The result conversion paircnvt_res,aux_res(see Table 8.7), specifies how this pointer is converted to a Self object before being returned. In thesockaddrexample, the proxy result conversion is used.classis the name of the class (or struct) that is being instantiated.gfname: the name of the C++ function that theCC_new_Nmacro expands into.ci,ai: if the constructor takes arguments, these arguments must be converted from Self representation to C++ representation. The arguments conversion pairsci,aispecify how each argument is converted. See Table 8.7 for a description of all argument conversions. In the sockaddr example, there are no arguments.
8.14.11. Deleting objects¶
C++ objects can have destructors that are executed when the objects are deleted. To ensure that the
destructor is called properly, the delete operator must know the type of the object being deleted.
This is ensured by using the CC_delete macro, which has the following form:
CC_delete(cnvt_obj,aux_obj, gfname)
For example, to delete sockaddr_in objects (constructed as in the previous section), the
CC_delete macro should be used in this manner:
CC_delete(proxy,(sockaddr_in *,socks), delete_sockaddr_in)
In general, the meaning of the arguments given to CC_delete is:
cnvt_obj,aux_obj: this pair can be any of the argument conversions found in Table 8.7 that produces a pointer to the object that will be deleted.gfname: the name of the C++ function that this invocation ofCC_deleteexpands into.
8.14.12. Calling member functions¶
Table 8.7 lists all the available argument conversions. Each row represents one conversion, with the first two columns designating the conversion pair. The third column lists the types of Self objects that the conversion pair accepts. The fourth column lists the C types that it produces. The fifth column lists the kind of errors that can occur during the conversion. Finally, the sixth column contains references to numbered notes. The notes are found in the paragraphs following the table.
Calling member functions is similar to calling “plain” functions, so please also refer to section Calling C functions. The difference is that an additional object must be specified: the object upon which the member function is invoked (the receiver in Self terms). Calling a member function is accomplished using one of the macros:
CC_mber_N(cnvt_res,aux_res, cnvt_rec,aux_rec, mname, gfname,
fail_opt, c0,a0, c1,a1, ..., cN,aN)
For example here is how to call the member function zock on a sockaddr_in object given by a
proxy:
CC_mber_0(bool,, proxy,(sockaddr_in *,socks), zock, zock_glue,)
The arguments to CC_mber_N are:
cnvt_res,aux_res: this pair, which can be any of the result conversions from Table 8.7, specifies how to convert the result of the member function before returning it to Self. For example, the zock member function returns a boolean.cnvt_rec,aux_rec: the object on which the member function is invoked. Often this will be a proxy conversion as in thezockexample.mnameis the name of the member function. In general, it may be any expression, such thatreceiver->mnameevaluates to a function.gfnameis the name of the C++ function that theCC_mber_Nmacro expands into.fail_opt: whether or not to pass a failure handle to the member function (refer to section Calling C functions for details).ci,ai: these are argument conversion pairs specifying how to obtain the arguments for the member function. Any conversion pair found in Table 8.7 may be used.
8.14.13. Conversion pairs¶
A major function of glue code is to convert between Self objects and C/C++ values. This conversion is guarded by so-called conversion pairs. A conversion pair is a pair of arguments given to a glue macro. It handles converting one or at most a few types of objects/values. There are different conversion pairs for converting from Self objects to C/C++ values (called argument conversion pairs) and for converting from C/C++ values to Self objects (called result conversion pairs).
8.14.14. Argument conversions – from Self to C/C++¶
An argument conversion is given a Self object and performs these actions to produce a corresponding C or C++ value:
- check that the Self object it has been given is among the allowed types. If not, report
badTypeError(invoke the failure block (if present) with the argument’badTypeError’).- check that the object can be converted to a C/C++ value without overflow or any other error. If not, report the relevant error.
- do the conversion, i.e., construct the C/C++ value corresponding to the given Self object.
| Conversion | Second part | Self type | C/C++ type | Errors | Notes |
|---|---|---|---|---|---|
| bool | boolean | int (0 or 1) | badTypeError | ||
| char | smallInt | char | badTypeError overflowError | 1 | |
| signed_char | smallInt | signed char | badTypeError overflowError | ||
| unsigned_char | smallInt | unsigned char | badSignError badTypeError overflowError | ||
| short | smallInt | short | badTypeError overflowError | ||
| signed_short | smallInt | signed short | badTypeError overflowError | ||
| unsigned_short | smallInt | unsigned short | badSignError badTypeError overflowError | ||
| int | smallInt | int | badTypeError | ||
| signed_int | smallInt | signed int | badTypeError | ||
| unsigned_int | smallInt | unsigned int | badSignError badTypeError | ||
| long | smallInt | long | badTypeError | ||
| signed_long | smallInt | signed long | badTypeError | ||
| unsigned_long | smallInt | unsigned long | badSignError | ||
| smi | smallInt | smi | badTypeError | 2 | |
| unsigned_smi | smallInt | smi | badSignError badTypeError | 2 |
| Conversion | Second part | Self type | C/C++ type | Errors | Notes |
|---|---|---|---|---|---|
| float | float | float | badTypeError | 3 | |
| double | float | double | badTypeError | 3 | |
| long_double | float | long double | badTypeError | 3 | |
| bv | ptr_type | byte vector | ptr_type | badTypeError | 4 |
| bv_len | ptr_type | byte vector | ptr_type, int | badSizeError badTypeError | 4, 5 |
| bv_null | ptr_type | byte vector/0 | ptr_type | badTypeError | 4, 6 |
| bv_len_null | ptr_type | byte vector/0 | ptr_type, int | badSizeError badTypeError | 4, 5, 6 |
| cbv | ptr_type | byte vector | ptr_type | badTypeError | 7 |
| cbv_len | ptr_type | byte vector | ptr_type, int | badSizeError badTypeError | 7 |
| cbv_null | ptr_type | byte vector/0 | ptr_type | badTypeError | 7 |
| cbv_len_null | ptr_type | byte vector/0 | ptr_type, int | badSizeError badTypeError | 7 |
| string | byte vector | char * | badTypeError nullCharError | 8 | |
| string_len | byte vector | char *, int | badTypeError nullCharError | 5, 8 | |
| string_null | byte vector/0 | char * | badTypeError nullCharError | 6, 8 | |
| string_len_null | byte vector/0 | char *, int | badTypeError nullCharError | 5, 6, 8 | |
| proxy | (ptr_type, type_seal) | proxy | ptr_type, != NULL | badTypeError badTypeSealError, deadProxyError,nullPointerError | 9 |
| proxy_null | (ptr_type, type_seal) | proxy | ptr_type | badTypeError badTypeSealError deadProxyError | 9 |
| any_oop | any object | oop | 10 | ||
| oop | oop subtype | corresponding object | oop (subtype) | badTypeError | 11 |
| any | C/C++ type | int/float/proxy/byte-vector, int | int/float/ptr/ptr | badIndexError badTypeError deadProxyError | 12 |
8.14.14.1. Notes¶
- The C type
charhas a system dependent range. Either 0..255 or -128..127.- The type
smiis used internally in the virtual machine (a 30 bit integer).- Precision may be lost in the conversion.
- The second part of the conversion is a C pointer type. The address of the first byte in the byte vector, cast to this pointer type, is passed to the foreign routine. It is the responsibility of the foreign routine not to go past the end of the byte vector. The foreign routine should not retain pointers into the byte vector after the call has terminated. Note: canonical strings can not be passed through a bv conversion (
badTypeErrorwill result). This is to ensure that they are not accidentally modified by a foreign function.- This conversion passes two values to the foreign routine: a pointer to the first byte in the byte vector, and an integer which is the length of the byte vector divided by
sizeof(*ptr_type). If the size of the byte vector is not a multiple ofsizeof(*ptr_type),badSizeErrorresults.- In addition to accepting a byte vector, this conversion accepts the integer 0, in which case a
NULLpointer is passed to the foreign routine.- The
cbvconversions are like the bv conversions except that canonical strings are allowed as actual arguments. Acbvconversion should only be used if it is guaranteed that the foreign routine does not modify the bytes it gets a pointer to.- All the string conversions take an incoming byte vector, copy the bytes part, add a trailing null char, and pass a pointer to this copy to the foreign routine. After the call has terminated, the copy is discarded. If the byte vector contains a null char,
nullCharErrorresults.- The
type_sealis anintorchar* expression that is tested against the type seal value in the proxy. If the two are different,badTypeSealErrorresults. The special valueANY_SEALwill match the type seal in any proxy. Note that theproxyconversion will fail withnullPointerErrorif the proxy object it is given encapsulates a NULL pointer.- The
any_oopconversion is an escape: it passes the Self object unchanged to the foreign routine.- The
oopconversion is mainly intended for internal use. The second argument is the name of an oop subtype. After checking that the incoming argument points to an instance of the subtype, the pointer is cast to the subtype.- The
anyconversion is different from all other conversions in that it expects two incoming Self objects. The actions of the conversion depends on the type of the first object in the following way. If the first object is an integer, the second argument must also be an integer; the two integers are converted to Cint’s, the second is shifted 16 bits to the left and they are or’ed together to produce the result. If the first object is a float, it is converted to a Cfloatand the second object is ignored. If the first object is a proxy, the result is the pointer represented by the proxy, and the second argument is ignored. If the first object is a byte vector, the second object must be an integer which is interpreted as an index into the byte vector; the result is a pointer to the indexed byte.
8.14.15. Result conversions - from C/C++ to Self¶
A result conversion is given a C or C++ value of a certain type and performs these actions to produce a corresponding Self object:
- check that the C/C++ value can be converted to a Self object with no overflow or other error occurring. If not, report the error.
- do the conversion, i.e., construct the Self object corresponding to the given C/C++ value.
Table 8.8 lists all the available result conversions. Each row represents one conversion, with the first two columns designating the conversion pair. The third column lists the type of C or C++ value that the conversion pair accepts. The fourth column lists the type of Self object the conversion produces. The fifth column lists the kind of errors that can occur during the conversion. Finally, the sixth column contains references to numbered notes. The notes are found in the paragraphs following the table.
| Conversion | Second part | C/C++ type | Self type | Errors | Notes |
|---|---|---|---|---|---|
| void | void | smallInt (0) | |||
| bool | int | boolean | |||
| char | char | smallInt | |||
| signed_char | signed char | smallInt | |||
| unsigned_char | unsigned char | smallInt | |||
| short | short | smallInt | |||
| signed_short | signed short | smallInt | |||
| unsigned_short | unsigned short | smallInt | |||
| int | int | smallInt | overflowError | ||
| signed_int | signed int | smallInt | overflowError | ||
| unsigned_int | unsigned int | smallInt | overflowError | ||
| long | long | smallInt | overflowError | ||
| signed_long | signed long | smallInt | overflowError | ||
| unsigned_long | unsigned long | smallInt | overflowError | ||
| smi | smi | smallInt | overflowError | ||
| int_or_errno | n | int | int | a UNIX error | 1 |
| float | float | float | 2 | ||
| double | double | float | 2 | ||
| long_double | long double | float | 2 | ||
| string | char * | byte vector | nullPointerError | 3 | |
| proxy | (ptr_type, type_seal) | ptr_type | proxy | nullPointerError | 3, 4, 8 |
| proxy_null | (ptr_type, type_seal) | ptr_type | proxy | 4, 8 | |
| proxy_or_errno | (ptr_type, type_seal, n) | ptr_type | proxy | a UNIX error | 4, 5, 8 |
| fct_proxy | (ptr_type, type_seal, arg_count) | ptr_type | fctProxy | nullPointerError | 3, 6, 8 |
| fct_proxy_null | (ptr_type, type_seal, arg_count) | ptr_type | fctProxy | 6, 8 | |
| oop | oop | corresponding object | 7, 8 |
8.14.15.1. Notes¶
- This conversion returns an integer value, unless the integer has the value n (the second part of the conversion; often -1). If the integer is n, the conversion interprets the return value as a UNIX error indicator. It then constructs a string describing the error (by looking at
errno) and invokes the “IfFail block” with this string.- Precision may be lost.
- This conversion fails with
nullPointerErrorif attempting to convert a NULL pointer.- The
ptr_typeis the C/C++ type of the pointer. Thetype_sealis an expression of type int orchar *.The conversion constructs a new proxy object, stores the C/C++ pointer in it and sets its type seal to be the value oftype_seal.- If the pointer is
n(oftennisNULL), the conversion fails with a UNIX error, similar to the wayint_or_errnomay fail.- The
fct_proxy,fct_proxy_nullandfct_proxy_or_errnoconversions are similar to the corresponding proxy conversions. The difference is that they produce afctProxyobject rather than a proxy object. Also, their second part is a triple rather than a pair. The extra component specifies how many arguments the function takes, if called. The special keywordunknownNoOfArgsor any nonnegative integer expression can be used here.- This conversion is an escape: it passes the C value unchanged to Self. It is an error to use it if the C value is not an
oop.- The
proxy(fctProxy) object that is returned by these conversions is not being created by the glue code. Rather aproxy(fctProxy) must be passed down from the Self level. Thisproxy(fctProxy), a result proxy, will then be side effected by the glue: the value that the foreign function returns will be stored in the result proxy together with the requested type seal. It is required that the result proxy is dead when passed down (else aliveProxyErrorresults). After being side-effected and returned, the result proxy is live. The result proxy is the last argument of the function that the glue macro expands to.
8.14.16. A complete application using foreign functions¶
This section gives a description of a complete application which uses foreign functions. The aim is
to present a realistic and complete example of how foreign functions may be used. The complete
source for the example is found in the directory objects/applications/serverDemo in the
Self distribution.
The example used is an application that allows Self expressions to be easily evaluated by non- Self processes. Having this, it then becomes possible to start Self processes from a UNIX prompt (shell) or to specify pipe lines in which some of the processes are Self processes. For example in
proto% cat someFile | tokenize | sort -r | capitalize | tee lst
it may be the case that the filters tokenize and capitalize perform most of their work in Self. Likewise, the command
proto% mail
may invoke some fancy mail reader written in Self rather than the standard UNIX mail reader.
To see how the above can be accomplished, please refer to Fig. 8.3 below. The left side of the figure shows the external view of a typical UNIX process. It has two files: stdin and stdout (for simplicity we ignore stderr). Stdin is often connected to the keyboard so that characters typed here can be read from the file stdin. Likewise, stdout is typically connected to the console so that the process can display output by writing it to the file stdout. Stdin and stdout can also be connected to “regular” files, if the process was started with redirection. The right side of Fig. 8.3 shows a two stage pipe line. Here stdout of the first process is connected to stdin of the second process.

Fig. 8.3 A single UNIX process and an pipe line.
Fig. 8.3 illustrates a simple trick that in many situations allows Self processes to behave as if they are full-fledged UNIX processes. A Self process is represented by a “real” UNIX process which transparently communicates with the Self process over a pair of connected sockets. The communication is bidirectional: input to the UNIX process is relayed to the Self process over the socket connection, and output produced by the Self process is sent over the same socket connection to the UNIX process which relays it to stdout. The right part of Fig. 8.3 shows how the UNIX/Self process pair can fit seamlessly into a pipe line.
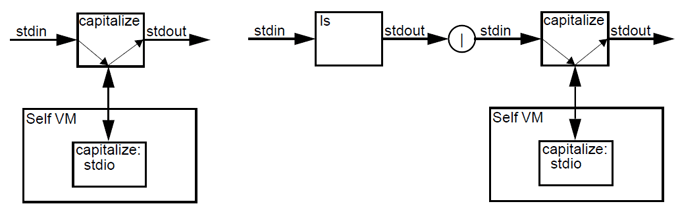
Fig. 8.4 A Self process and how it fits into a pipe line.
Source code that facilitates setting up such UNIX/Self process pairs is included in the Self distribution.
The source consists of two parts: one being a Self program (called server), the other being
a C++ program (called toself). When the server is started, it creates a socket, binds a name to it
and then listens for connections on it. toself establishes connections to the server program. The
first line that is transmitted when a connection has been set up goes from toself to the server. The
line contains a Self expression. Upon receiving it, the server forks a new process to evaluate the
expression in the context of the lobby augmented with a slot, stdio, that contains a unixFile-like
object that represents the socket connection. When the forked process terminates, the socket connection
is shut down. The toself UNIX process then terminates.
The Self expression that forms the Self process is specified on the command line when toself
is started. For example, if the server has been started, the following can be typed at the UNIX
prompt:
proto% toself stdio writeLine: 5 factorial printString
120
proto% echo something | toself capitalize: stdio
SOMETHING
proto% toself capitalize: stdio
Write some text that goes to stdin of the toself program
WRITE SOME TEXT THAT GOES TO STDIN OF THE TOSelf PROGRAM
More text
MORE TEXT
^D
proto%
If you want to try out these examples, locate the files server.self, socks.so and toself. The
path name of the file socks.so is hardwired in the file server.self so please make sure that it
has been set correctly for your system. Then file in the world and type [server start] fork at
the Self prompt. Now you can go back to the UNIX prompt and try out the examples shown
above.
8.14.17. Outline of toself¶
toself is a small C++ program found in the file toself.c. It operates in the three phases outlined
above:
- Try to connect to a well-known port number on a given machine (the function
establishConnectiondoes this).- Send the command line arguments over the connection established in 1 (the
safeWritecall inmaindoes this).- While there is more input and the Self process has not shut down the socket connection, relay from stdin to the socket connection and from the socket connection to stdout (the function
relaydoes this).
8.14.18. Outline of server¶
The server is a Self program. It is found in the file server.self. When the server is started, the
following happens:
- Create a socket, bind a name to it and start listening.
- Loop: accept a connection and fork a new process (both step 1 and 2 are performed by the method
server start). The forked process executes the methodserver handleRequestwhich:
- Reads a line from the connection.
- Sets up a context with a slot
stdioreferring to the connection.- Evaluates the line read in step (a) in this context.
- Closes the connection.
8.14.19. Foreign functions and glue needed to implement server¶
The server program needs to do a number of UNIX calls to create sockets and bind names to them
etc. The calls needed are socket, bind, listen, accept and shutdown. The first three of these
are only called in a fixed sequence, so to make things easier, a small C++ function
socket_bind_listen, that bundles them up in the right sequence, has been written. The accept
function is more general than what is needed for this application, so a wrapper function,
simple_accept, has been written. The result is that the server needs to call only three foreign
functions: socket_bind_listen, simple_accept and shutdown. Glue for these three functions
and the source for the first two is found in the file socks.c. This file is compiled and linked
using the Makefile. The result is a shared object file, socks.so.
8.14.20. Use of foreign functions in server.self¶
The server program is implemented using foreignFct objects. There is only a few lines of code
directly involved in setting this up. First the foreignFct prototype is cloned to obtain a “local
prototype”, called socksFct, which contains the path for the socks.so file. socksFct is then
cloned each time a foreignFct object for a function defined in socks.so is needed. For example,
in traits socket, the following method is found:
copyPort: portNumber = ( "Create a socket, do bind, then listen."
| sbl = socksFct copyName: ’socket_bind_listen_glue’. |
sbl value: portNumber With: deadCopy.
).
This method copies a socket object and returns the copy. The local slot sbl is initialized to a
foreignFct object. The body of the method simply sends value:With: to the foreignFct
object. The first argument is the port number to request for the socket, the second argument is a
deadCopy of self (socket objects are proxies and socket_bind_listen returns a proxy, so it
must be passed a dead proxy to revive and store the result in; see section Proxy and fctProxy objects).
There are only three uses of foreignFct objects in the server and in all three cases, the foreignFct
object is encapsulated in a method as illustrated above.
In general the design of foreignFct objects has been aimed at making the use of them light
weight. When cloning them, it is only necessary to specify the minimal information: the name of
the foreign function. They can be encapsulated in a method thus localizing the impact of redesigns.
The complications of dynamic loading and linking are handled automatically, as is the recovery of
dead fctProxies.
Footnotes
| [1] | The bracketed colon indicates that the argument is optional (i.e., there are two versions of the primitive, one taking an argument and one not taking an argument). The bracket is not part of the primitive name. See text for details. |